

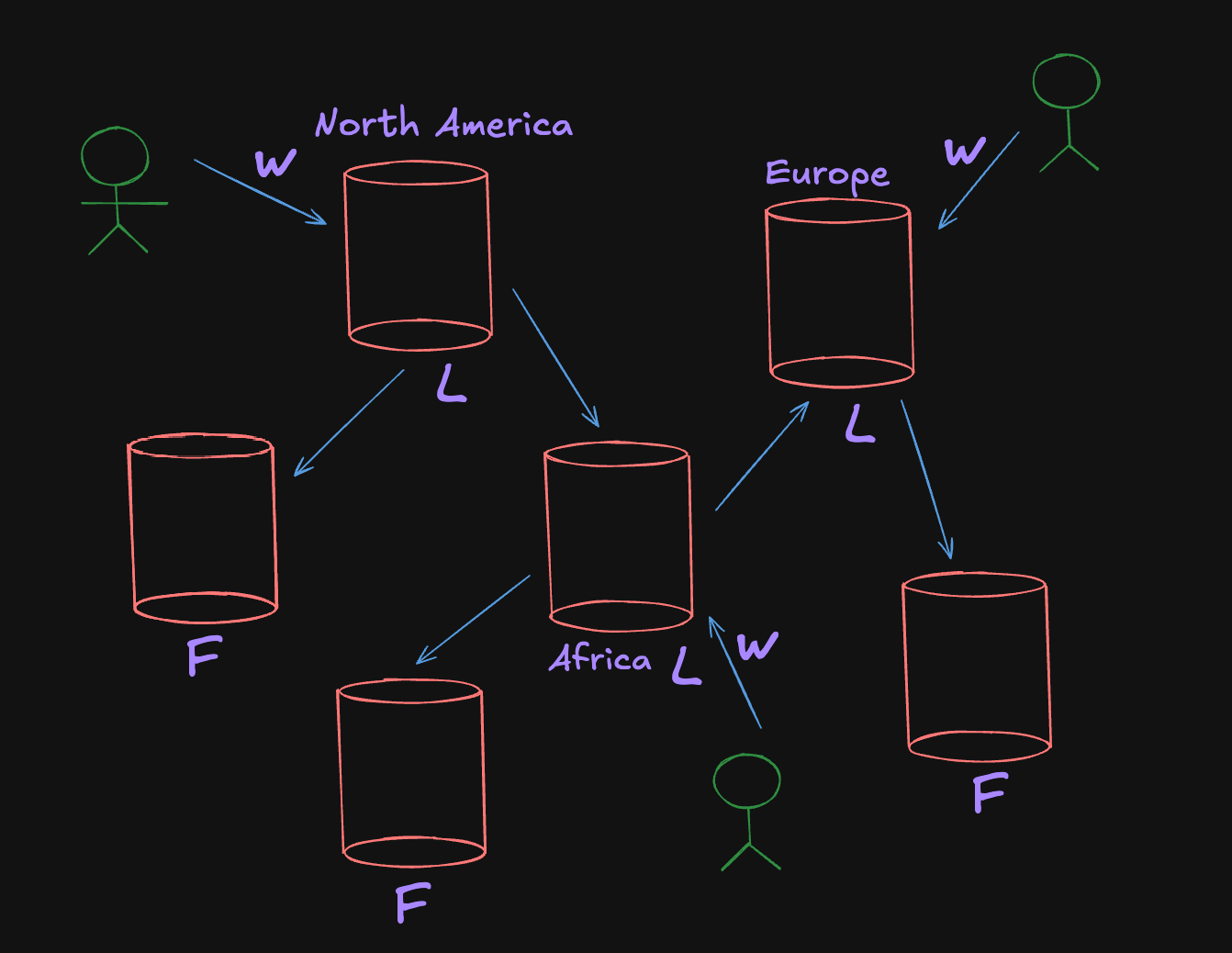
As you can see in the diagram, we have a few leader (L) and follower (F) nodes in that setup.
Well, the point here is, that anyone can write any of the leaders & they can write anything & we can still only read from the followers. And, the followers would be getting those writes propagated to them probably asynchronously.
It affords us more write throughput because we can write at different places now.
Additionally, If you can see the diagram. The guy in Europe doesn’t have to write all the way to North America because it will take time as both are further apart.
Heaving leaders at different places makes a life lot easier. They still pass the writes to one another. And, there are many other configurations for this also k/a topologies.
Topologies
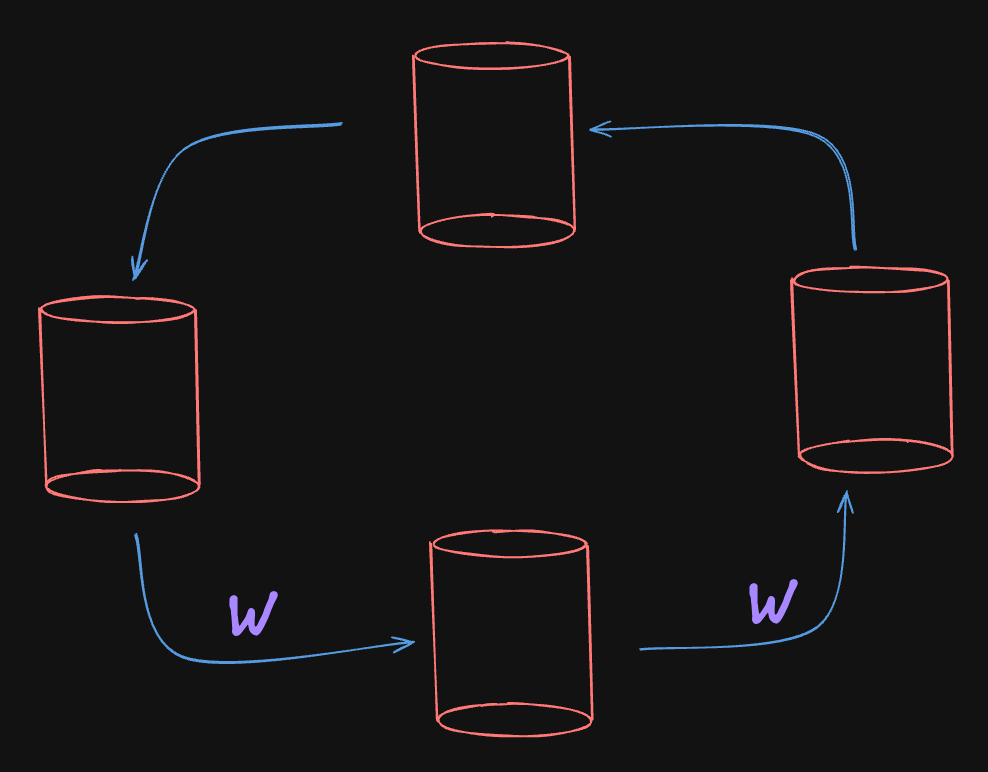
Circle Topology
This is a pretty simple topology. Imagine all the nodes are leaders (L) and they would pass writes to the next node. But the problem is If one node goes down the entire configuration would be dead. So, it doesn’t save you from single-node failure. They. don’t have durability and protection for this.
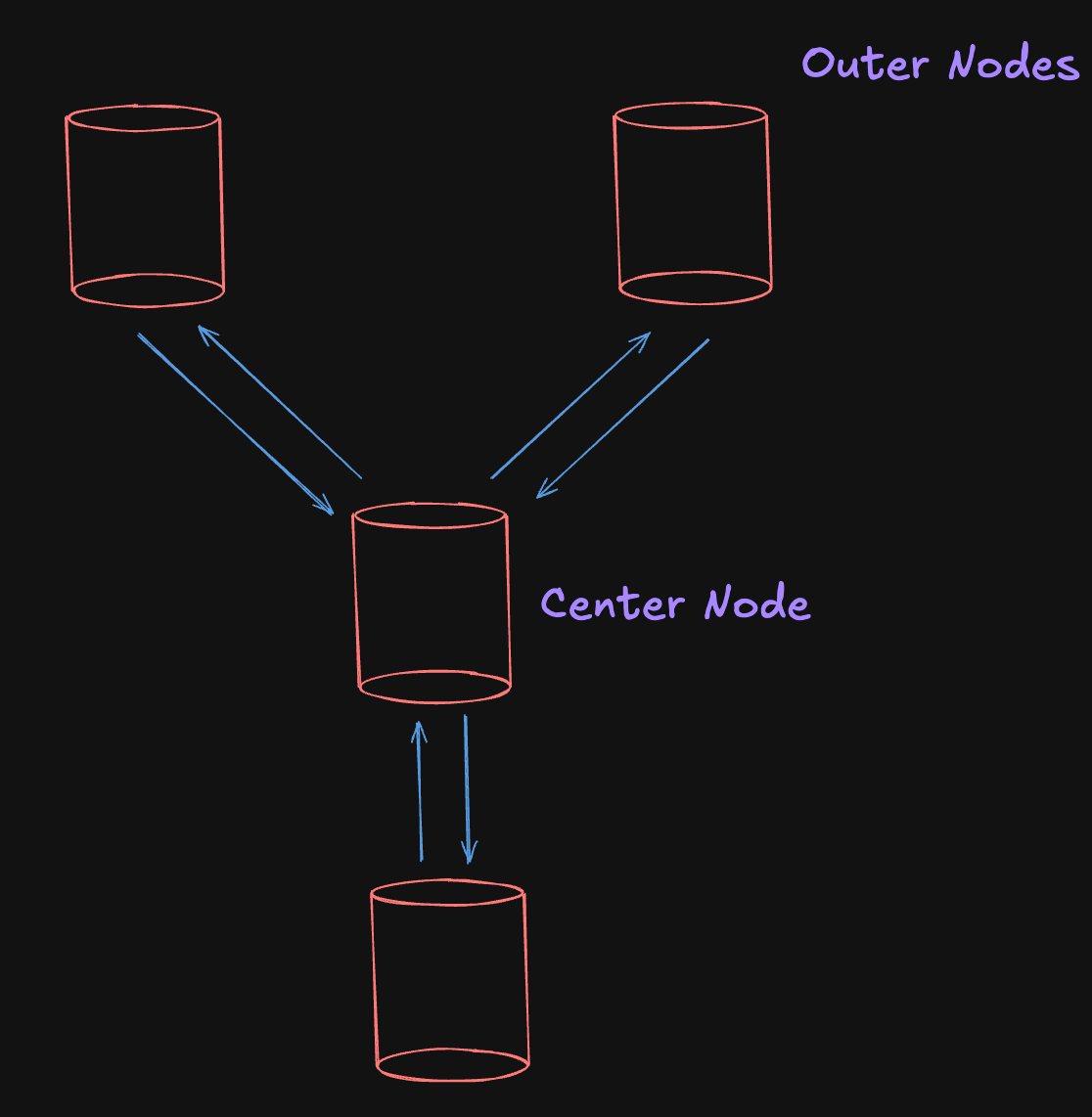
Star Topology
To fix circle topology, Star is the possible solution. In this config, we have one center node and a bunch of outer nodes. The outer nodes pass the writes to the center node. And, in return center node distributes them to the rest of the node.
If one of the outer nodes goes down then the system is still alive and nodes communicate with each other. If the center node fails, then the system collapses which leads to a failure.
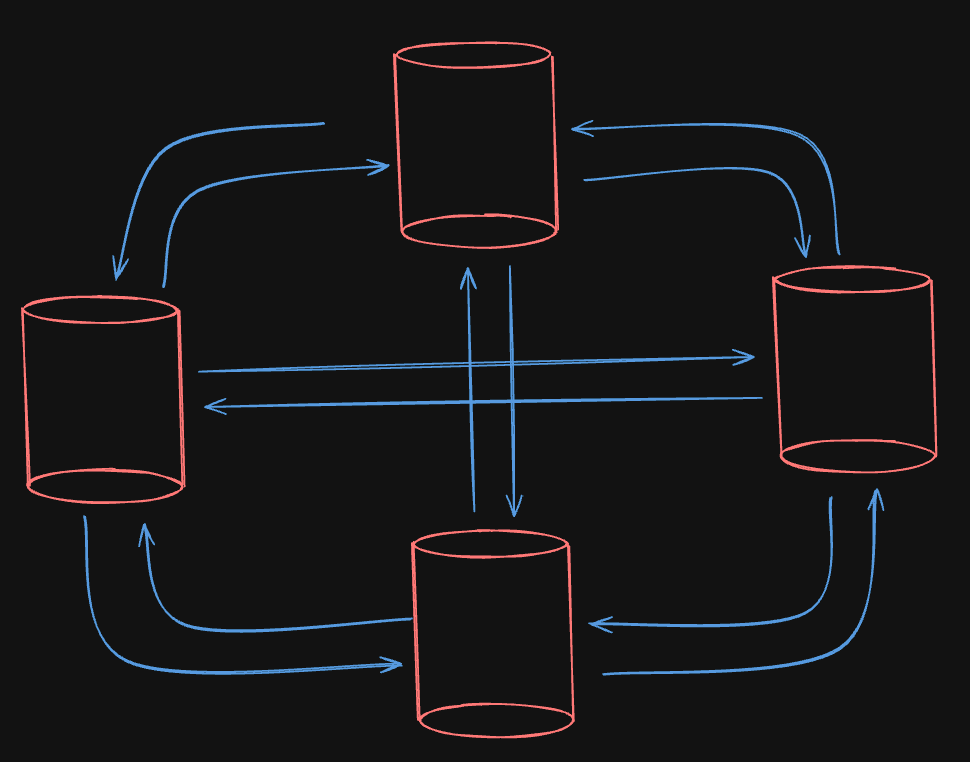
All to All Topology
Well, in this system, if a single node goes down. It’s not a problem because the system would still be running fine. All the nodes would communicate with each other anyway.
But there is still a problem in terms of writes. It could create write conflicts in the system. Writes can get out of order in this system but it is fixable.
Replication Log
So, how can they get out of order and out of whack & how can we make sure that messages that are bouncing around the databases all over the place? So, we wanna make sure that all of these writes are not being applied multiple times on every single db node. To fix this we need to make changes in the replication log to ensure that writes aren’t being bounced around forever.
So, every single db can keep track of which writes it applied but it can take that write & send it to other db nodes if it thinks that they haven’t seen it yet. We need to modify the replication log, to keep track of which writes in the replication log have been seen by which db node.
Modifying Replication Log

This diagram is useful. It shows which replicas have seen the writes that make sure we aren’t just passing the message around indefinitely and possibly even applying it more than once because that could be really problematic.
Write Conflicts
Let’s talk about write conflicts.
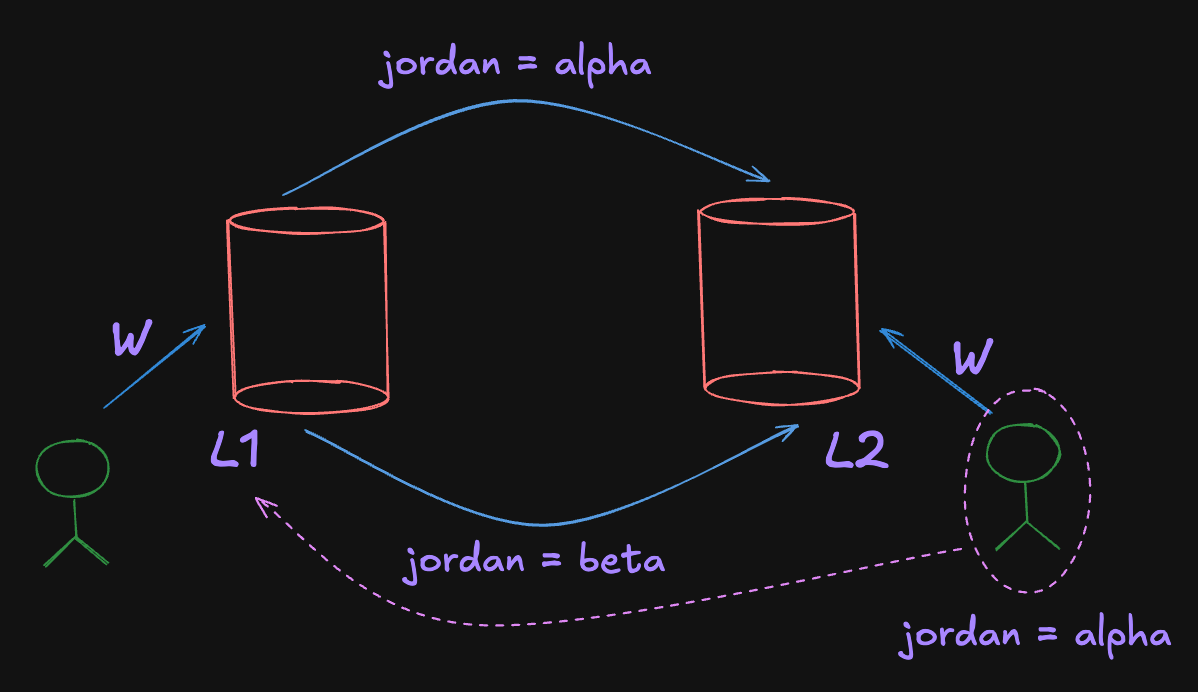
In multiple leader replication, we have an issue called writes conflicts because we can now write to multiple places. According to the diagram, we have 2 guys one is writing jordan=alpha and other writes jordan=beta at the same time. When L1 and L2 will pass the writes to each other regardless of topology, how do we actually know whether jordan=alpha or jordan=beta because they are written basically at the same time.
We are assuming, that the person who wrote jordan=alpha doesn’t know about jordan=beta when they wrote it. And, vice versa also. What this means is, these 2 writes are concurrent and now we have to resolve a write b/w them. One easy solution is known as “Conflict avoidance”. It says, that all writes to the same key are going to the same replica.
So, what we can do is instead of the person writing to L2, we can let that person write to L1. So, when it writes jordan=beta then alpha and beta is going to get there first and one of them is going to win. On the other hand, this is going to limit write throughput. Because all of our guys will write to the same replica.
Last Write Wins
Now, one strategy to avoid write conflicts is “Last Write Wins”.
So, every single write is going to have a timestamp. Let's say I’m writing jordan=alpha at 4 O’clock. Now, we can use this timestamp to decide if I write jordan=alpha at 4 O’clock and someone else writes jordan=beta at 4 O’clock then jordan=beta is the more up-to-date value. In theory, it does work but in reality, it has a lot of problems.
Well, the first problem is what timestamp do we use? Do we use the timestamp of the sender? Well probably not, it is not a good idea. Because someone can manipulate their device’s timestamp and in that case, his writes always going to win.
On the contrary, we could use a timestamp for the receiver. We could actually use the timestamp on the 2 individual leader nodes to determine which write is recent. Now, technically it does work but if we can rely on the timestamps. Hence, it is important that the timestamp must be accurate but it is easy not to do so. This leads to the last writes at the end of the day.
There is not a great solution to solve write conflicts. There is no hard and fast rule to look at 2 writes and say “one is definitely came before the other”.