

Hashmaps are an essential data structure to work with, but often we don't fully understand how they operate. Today, we’ll build a custom hashmap from scratch and explore some key operations like get, put, remove, and more. Let’s dive in.
When designing a hashmap, it’s important to consider its default size, maximum capacity, and load factor. Typically, a hashmap starts with a default size of 16. It’s also crucial that the hashmap’s size is always a power of 2, as this improves collision management. For this implementation, we’ll set the maximum capacity to 2^30. Additionally, we’ll use a load factor of 75%, meaning the hashmap will resize when it reaches 75% of its capacity.
Few variables we need to initialize

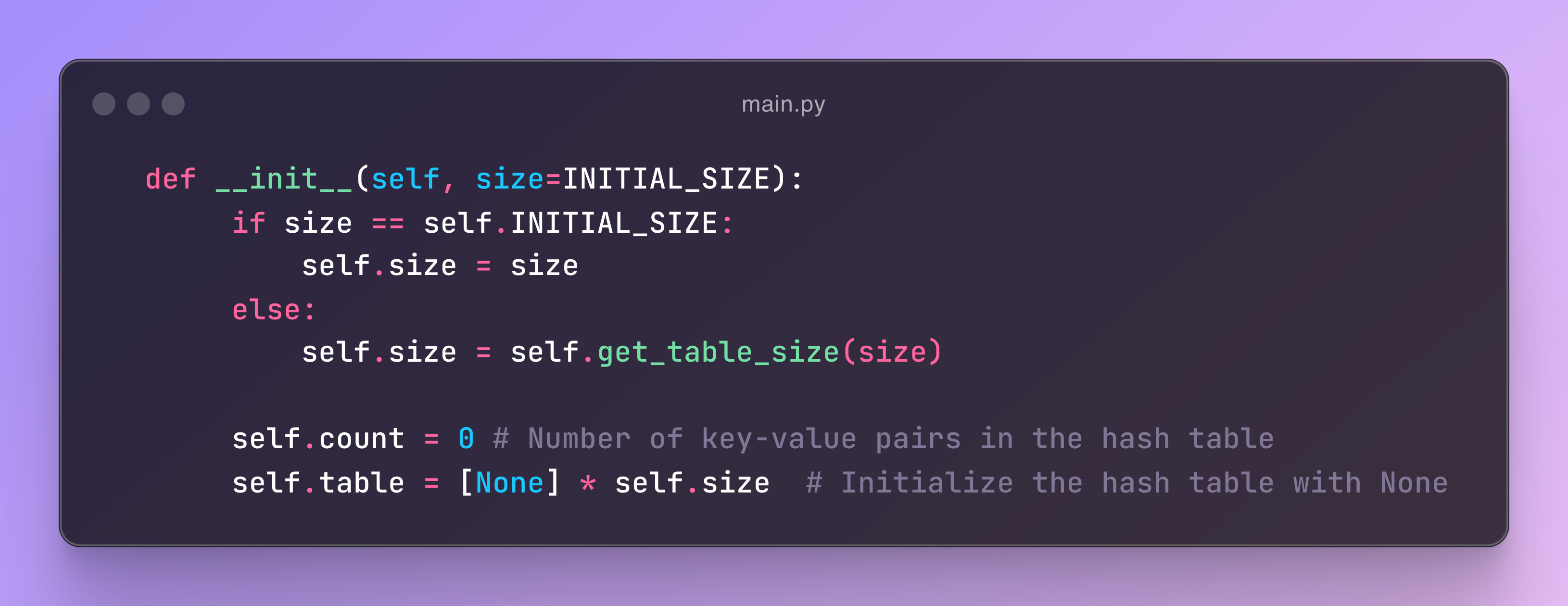
Constructor
The constructor function will use a default size, INITIAL_SIZE, as mentioned in the code snippet. This means that if the user creates a hashmap without specifying a size, the default size will be used. However, if the user provides a size, it will be passed to the get_table_size function, which we will briefly discuss. Additionally, there is a count variable that keeps track of the number of key-value pairs in the hashmap, and table, which represents the hash table itself.
get_table_size() function
Well, it computes the next power of 2 greater than or equal to the provided capacity, but with some safeguards to avoid exceeding a maximum capacity. The goal of this method is to find the smallest power of 2 that is greater than or equal to the input capacity.

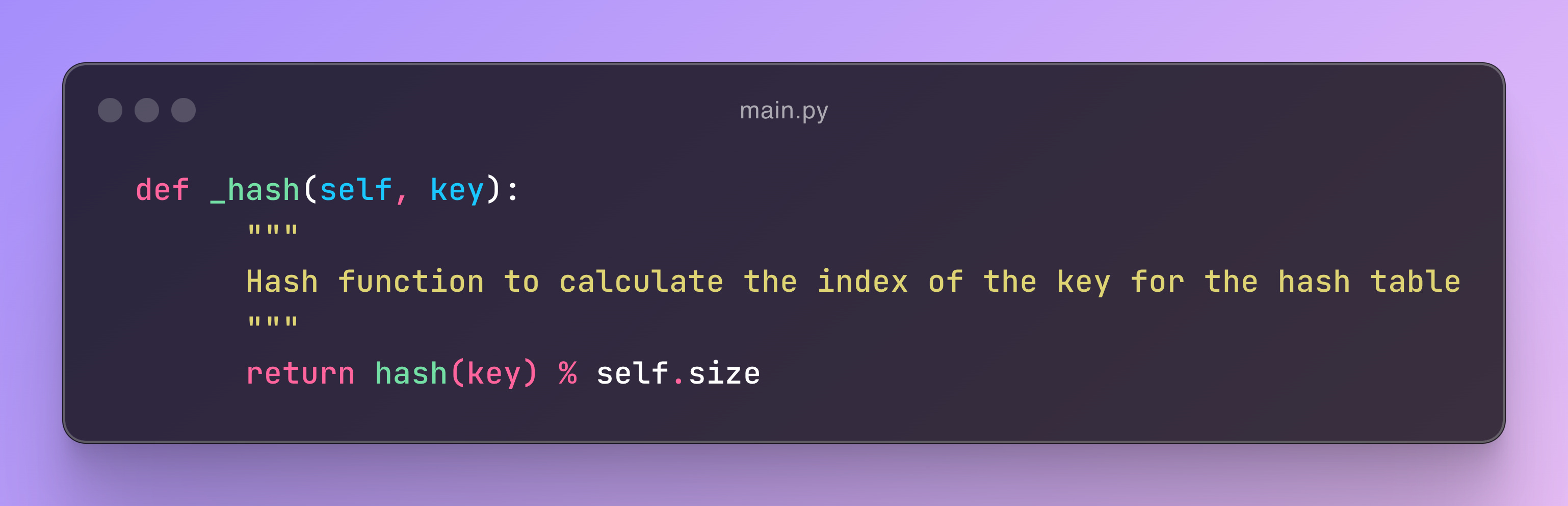
Hash Function
We use a hash function to determine the index for a given key, and then store the corresponding key-value pair at that index in the hash table. For simplicity, we've utilized Python's built-in hash function.
The _hash function calculates the index for a given key in a hash table by applying Python's built-in hash() function to the key and then taking the remainder when divided by the table's size. This ensures the key is mapped to a valid index within the table's range.
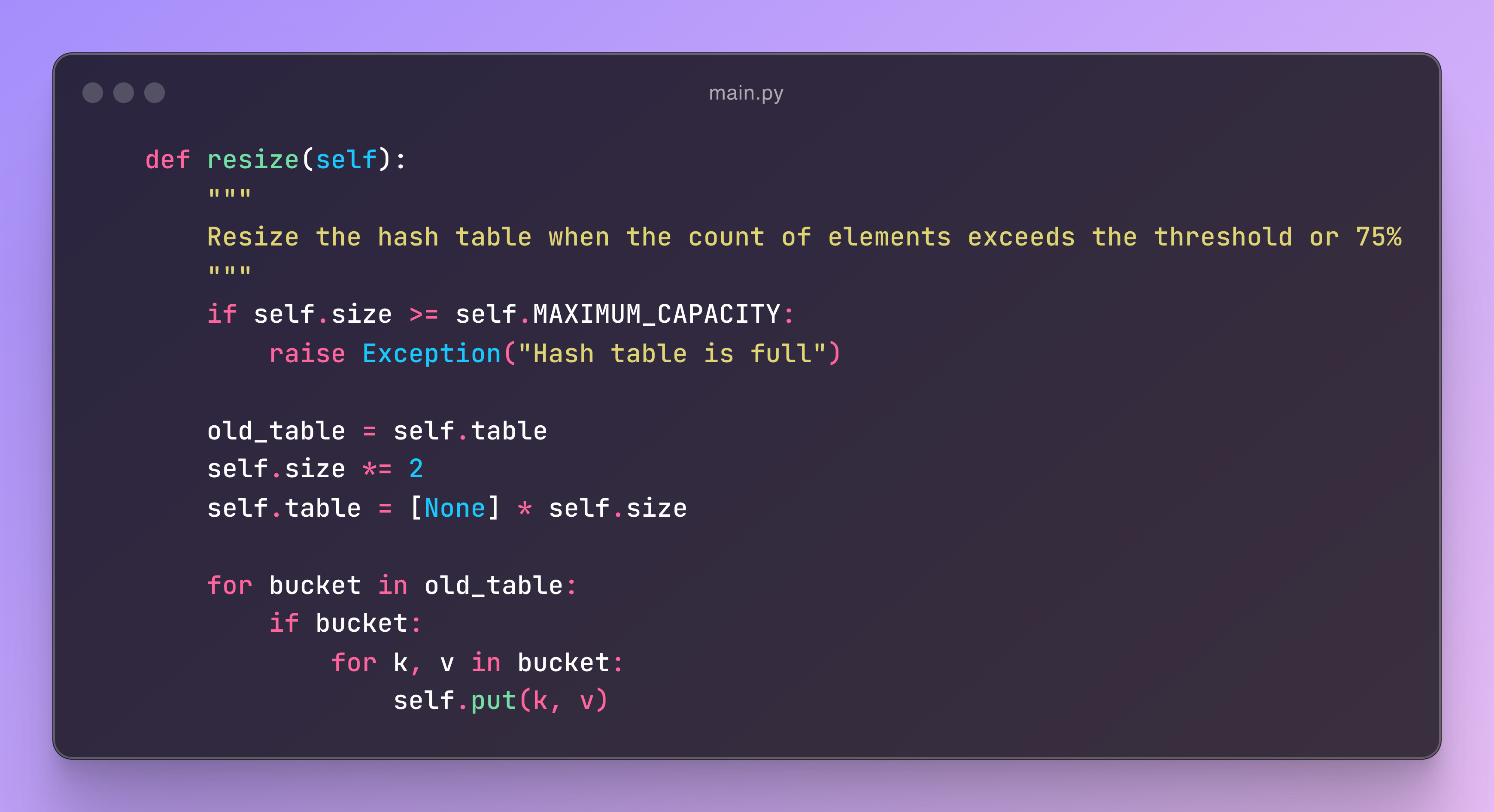
Resize Function
The resize function is straightforward with only two scenarios. If the size exceeds the maximum capacity, it throws an error like "Hash Table is full." Otherwise, it simply doubles the size of the table.
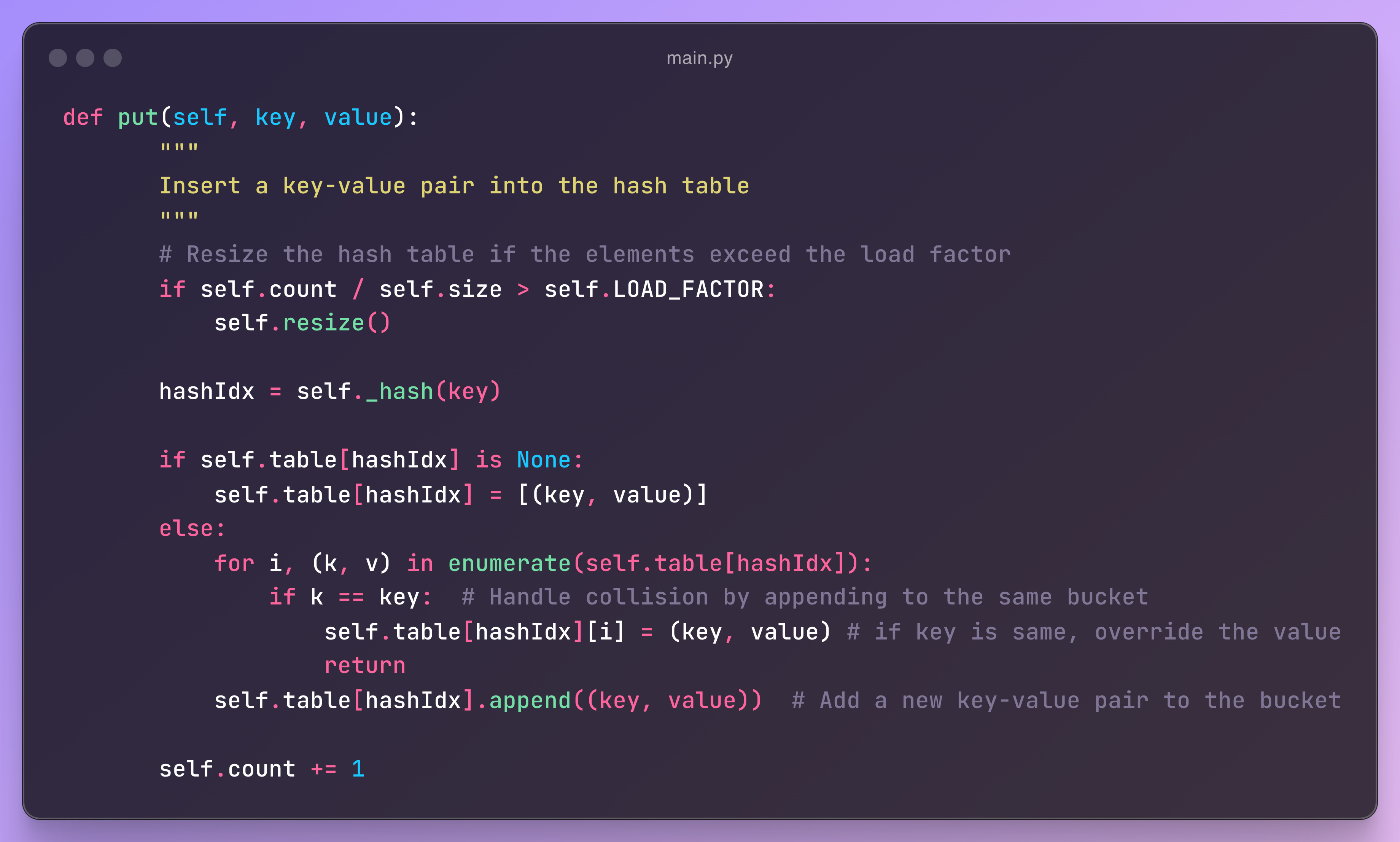
Put Function
The put function inserts a key-value pair into a hash table. It first checks if resizing is needed based on the load factor. Then, it calculates the index for the key using a hash function. If the index is empty, it adds the pair; if there’s a collision, it either updates the existing pair or appends the new pair to the bucket. Finally, it increments the element count.
Get Function
The get function retrieves the value for a given key in the hash table. It hashes the key to find the corresponding index, then searches for the key in the bucket at that index. If found, it returns the associated value; otherwise, it returns None.
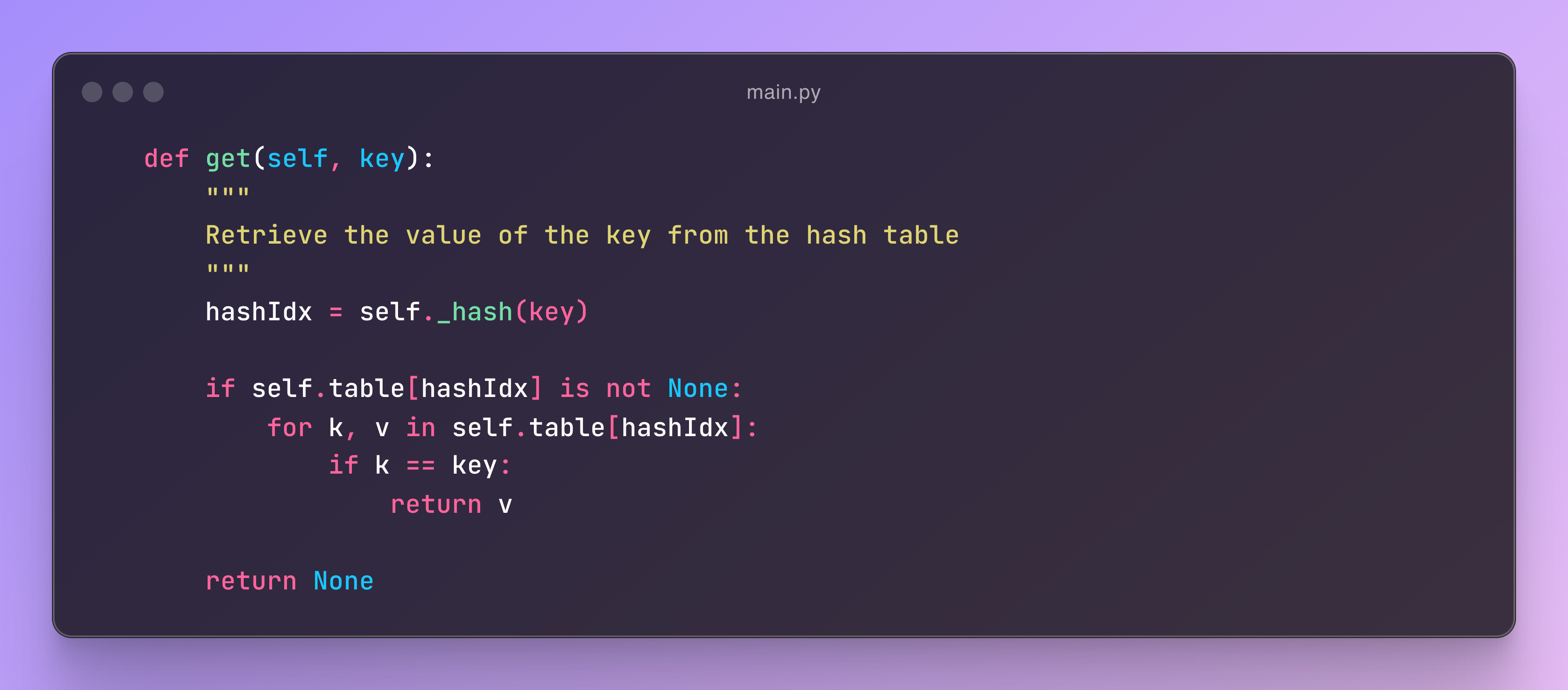
Remove Function
The remove function removes the key-value pair for the given key from the hash table. It hashes the key to find the appropriate index in the table. If the bucket at that index contains the key, it deletes the pair, updates the count, and returns True. If the key is not found, it returns False.
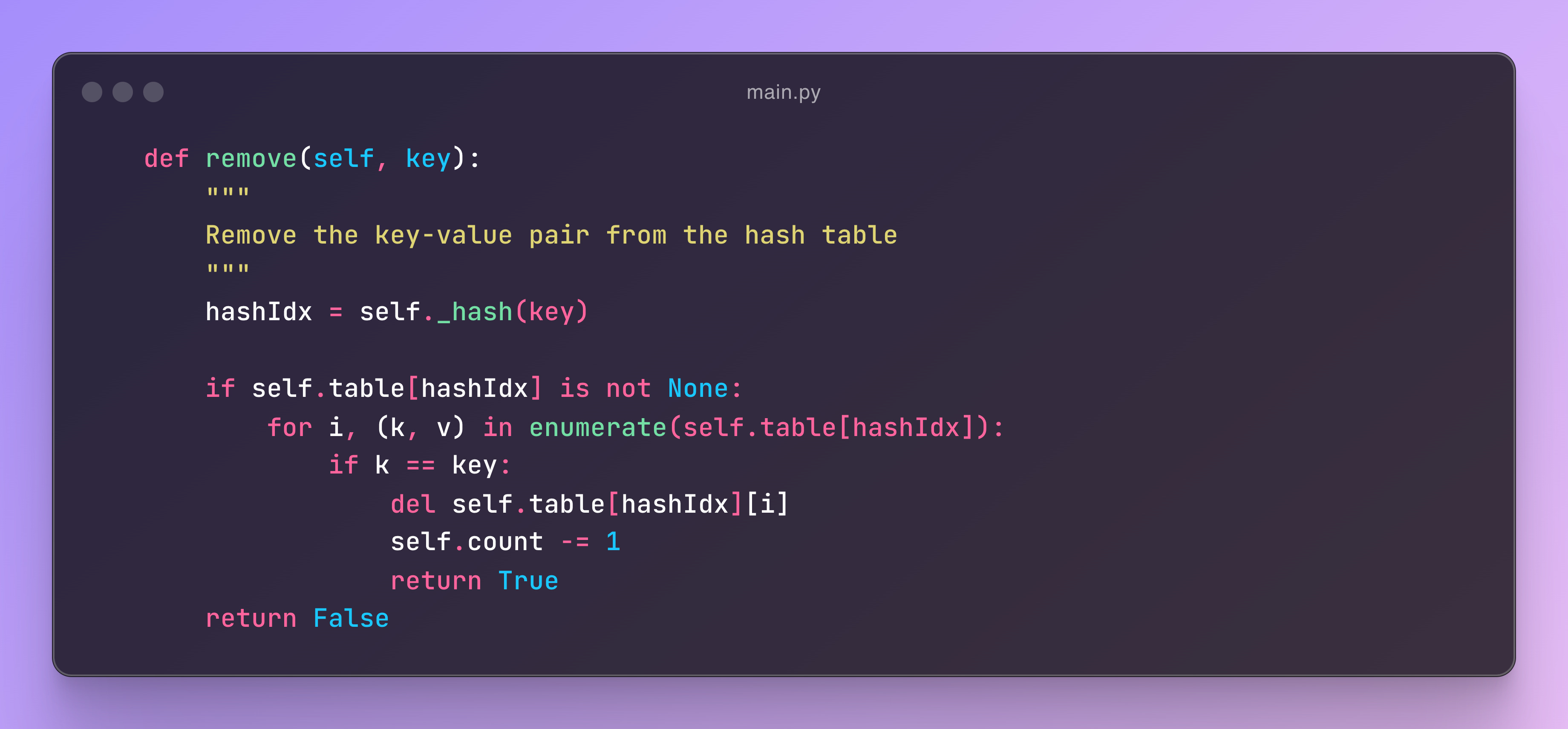
String Representation
Ideally, the __str__ function is a special method in Python that defines how an object should be represented as a string when you print it or call str() on it. In this case, the __str__ function provides a string representation of the hash table. It loops through all the buckets in the table, collects the key-value pairs, and formats them into a string like a dictionary, making the hash table easier to inspect when printed or converted to a string.
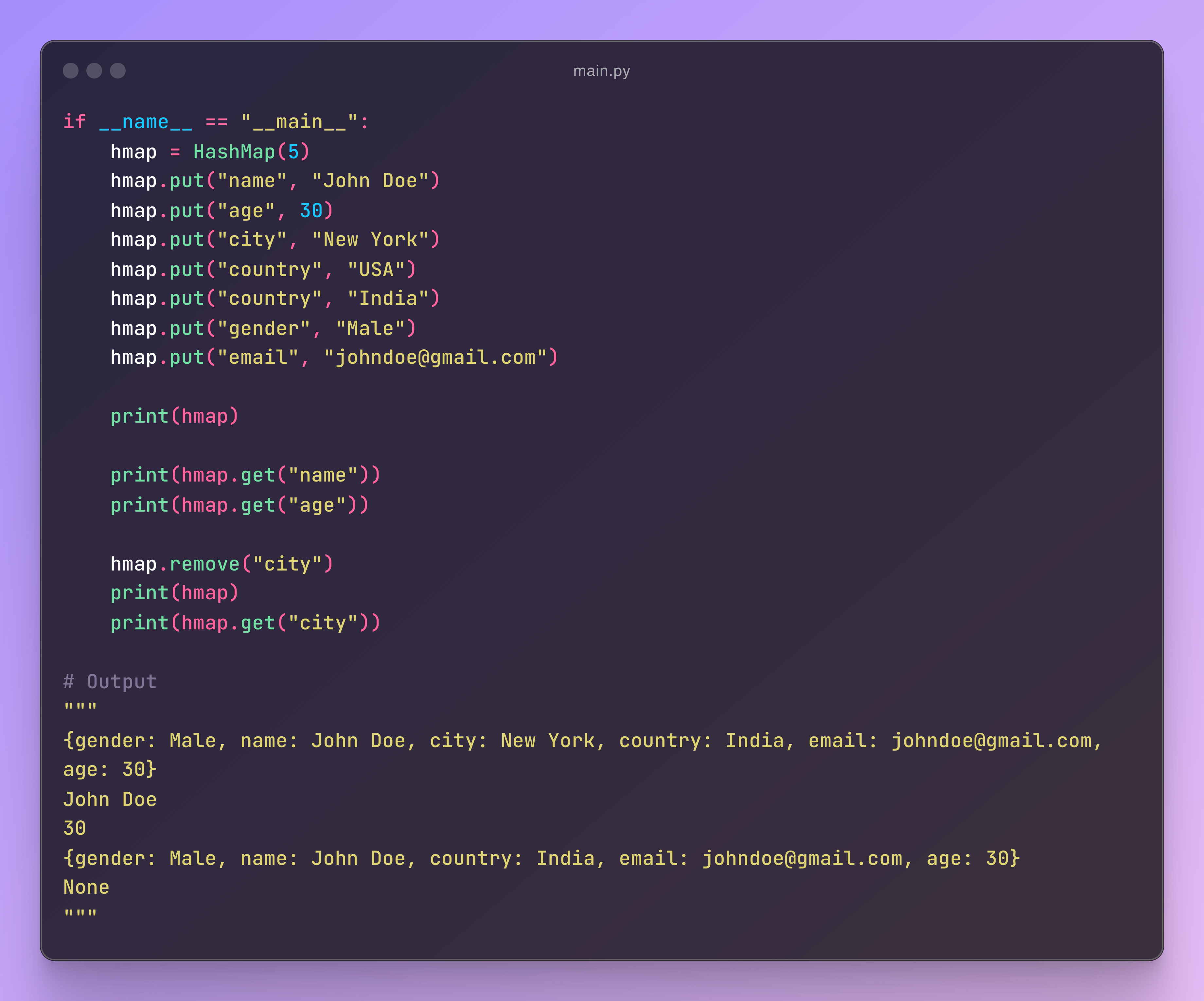
The main function and calling the Hashmap
Finally, we simply call our HashMap to observe how it operates in practice. As you can see, we've used all the key functions like get, put, and remove to demonstrate the functionality of our hash table.
Caveats
After all of these, there are a few caveats we need to discuss.
We are currently using Python's built-in
hashfunction and modulus operation, which is fine for general purposes. For performance in large-scale systems, consider implementing your own hashing strategy to minimize clustering.Our collision handling is very basic but functional. We are using chaining with lists, but we could use a separate class for the bucket such as a linked list to make it more robust and maintainable. Lists could work as long as operations like search remain efficient.
If you would like to see the whole implementation, head over to this link: https://github.com/thisisnitish/low-level-design/blob/main/Hashmap/main.py